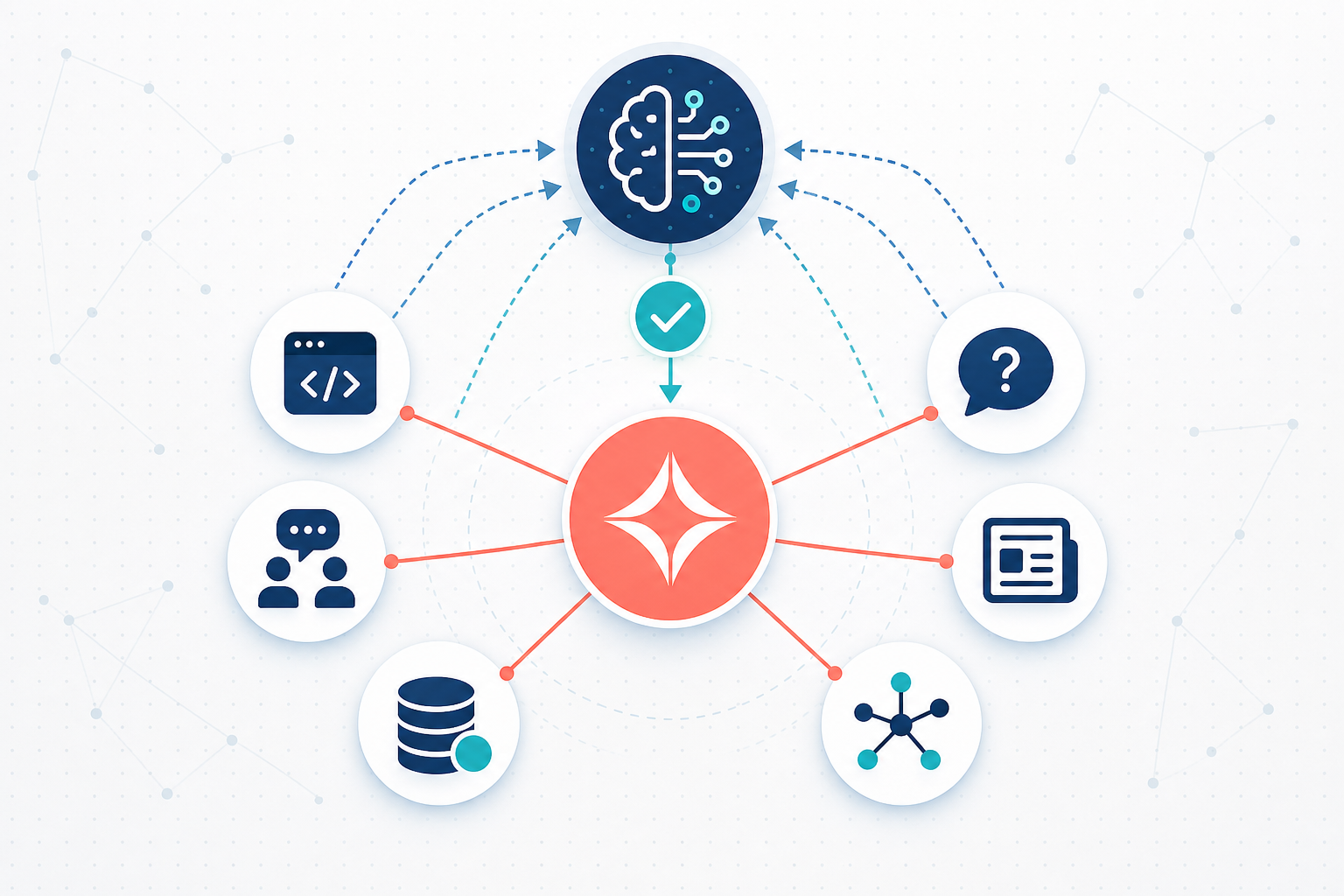
一个常见的误区是:把官网打磨到极致,就能让大模型推荐你。但 ChatGPT 在回答「推荐哪款 GEO 监测工具」时,它的隐式判断其实接近于「哪个品牌被足够多彼此独立的来源提到、且评价正面」。在这套逻辑里,一个自说自话的官网权重很低,真正起作用的是全网范围的共识。这篇讲的就是站外内容该铺在哪、怎么写。
大模型推荐品牌时,实际在看三件事
- 实体出现频率:同一品牌在多少个语义独立的文本片段里出现。频率越高,模型越倾向把它当成行业共识。
- 文本客观性:带强营销腔的段落(感叹号、「全球第一」「绝对最优」)会被模型内部滤波降权,技术论坛、新闻报道、学术摘要的客观性评分更高。
- 来源多样性:五个独立平台各提一次,胜过同一个官网自我重复五次。
平台优先级清单
不同平台在 AI 训练与检索中的权重差异很大。下面按优先级(兼顾中英文市场)排列,并给出各自的正确打开方式。
技术与开发者平台(权重最高)
- GitHub:建一个 Awesome 列表或工具对比仓库,把自己和竞品客观并列。README 是 GPTBot 的重点抓取对象,常被当作「中立清单」引用。
- Stack Overflow / 掘金 / SegmentFault:用你的产品解决一个真实技术问题,写成问答。聚焦问题本身,广告腔既会被模型降权,也会被社区折叠。
知识与资讯平台
- 知乎:在「GEO」「AI SEO」「大模型营销」等话题下回答高赞问题。知乎内容被国内大模型大量收录,是中文市场的关键阵地。
- 少数派 / 36氪 / 虎嗅:以行业趋势分析、深度评测的形式投稿,自然带入品牌。纯软文会被编辑退回,必须有真实洞察。
- Reddit(英文市场):r/SEO、r/marketing 等版块。OpenAI 在 2024 年与 Reddit 达成官方数据授权合作,其内容在 ChatGPT 语料里权重很高。
结构化实体平台(建立事实底座)
- Wikidata:为公司创建实体,填写官网、成立时间、所属行业。它是 Google 知识图谱与多家大模型的基础实体库,能显著降低大模型对你的「幻觉率」。
- Crunchbase / 企查查:保证公司信息完整准确,这些是大模型做公司事实核查时的常用信源。
一个被低估的技巧:实体相邻效应
在文章里主动、客观地把品牌和头部竞品并排对比,不要回避竞品。大模型检索竞品时,会顺带召回与之「语义相邻」的实体,也就是你。一篇「A、B、C 三款工具横评」的客观文章,往往比一篇「A 有多好」的独白,更能让 A 在 AI 回答里反复出现。
描述有误时,用回链快速纠错
如果第三方已经提到你、但把功能讲错了,最快的纠错方式是在官网建一个「媒体报道 / 品牌资料包」页面,用 JSON-LD 的 mentions 字段把这些报道关联起来,同时联系原作者请求更正。大模型下次检索会同时抓到官方与第三方双重信源,准确的版本更容易被采信。
站外布局不是一次性发稿,而是持续让「独立来源、客观评价、多平台」这三个变量一起增长。三者形成稳定的全网共识后,AI 才会在无人提示时主动把你写进答案。