“为什么大模型不知道我”几乎是所有刚接触 GEO 的人问的第一个问题。但这个问题本身就是错的,大模型“知道”你有两条完全独立的路径,把它们混为一谈,就会得出错误的结论和错误的修复动作。这篇问答把机制讲透,让你能自己定位问题出在哪一段。
问:大模型到底怎么“知道”我网站的内容?
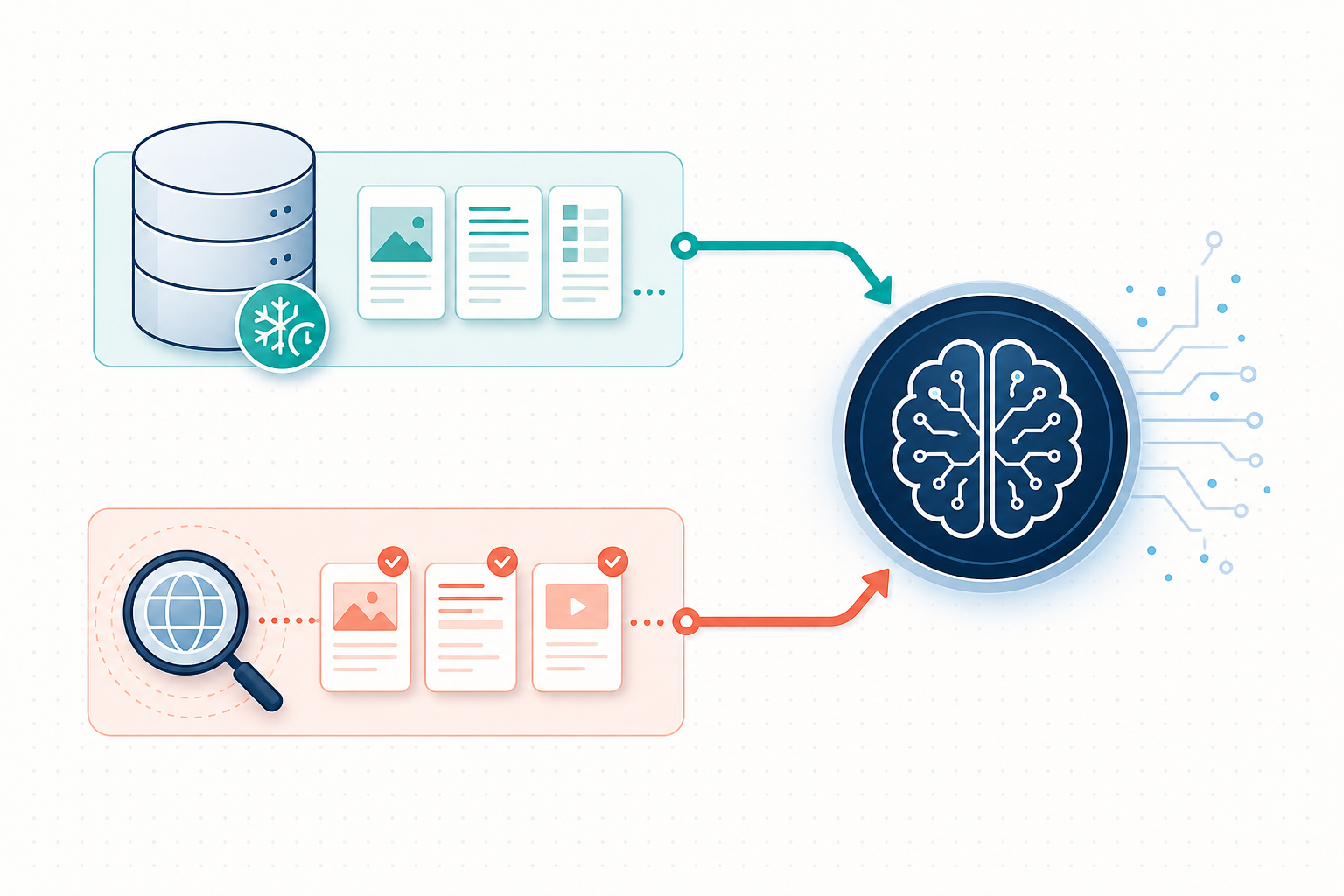
两条路径,必须分开看:
- 训练语料(静态记忆):厂商在训练 GPT、Claude、文心等模型之前,会用大规模爬虫把公开网页抓下来做语料。这是一次性的:训练完成,模型内部的“记忆”就冻结了,并带有一个知识截止日期(training cutoff)。之后你官网的任何更新,模型都不知道,除非下一次重新训练。
- 实时联网检索(RAG):用户用联网模式提问时,系统会当场调用搜索接口(Bing、自研爬虫等),把关联最高的页面抓下来拼成背景材料,再喂给模型生成回答。这条路径没有截止日期,但取决于中间的搜索引擎是否已收录并更新了你的页面。
所以,“大模型不知道我”其实是两个独立问题:训练语料里没收录你,或搜索引擎缓存没更新。两者的修复手段截然不同。
问:我昨天改了产品价格,为什么 ChatGPT 给的还是旧价?
这是 RAG 链条的延迟,不是模型的 bug。常见原因有三个:
- 搜索缓存未更新:ChatGPT 联网底层多走 Bing。Bing 还没重新抓取你的页面,拿到的自然是旧数据。Bing Webmaster Tools 支持手动提交 URL 申请优先爬取,一般 1 到 3 天生效。
- robots.txt 屏蔽了实时爬虫:很多人只盯着 GPTBot(训练爬虫),却忽略了 ChatGPT-User(联网检索爬虫)。后者被挡,实时检索直接失败。
- WAF 拦截了爬虫 IP:Cloudflare 等默认对 Bot 流量有拦截策略,AI 爬虫的 IP 段可能被当成可疑 Bot,需要手动加白名单。
问:我既没做 GEO 也没配 JSON-LD,为什么大模型还是提到了我?
说明你的品牌已经在训练语料里留下了印记,通常来自被收录的第三方媒体、行业报告、百科词条,或者用户在知乎、Reddit、GitHub 这些高权重平台讨论过你。但这种“自然提及”通常是零散的,大模型对你的描述可能不完整甚至有误。GEO 的意义就是让你主动控制这个叙事,而不是靠运气(如何系统地经营第三方提及,见本站《第三方生态布局实战》)。
问:训练语料和实时检索,我该优先攻哪个?
短期看实时检索。训练语料的更新周期以“月到年”计,单次优化很难快速进入静态记忆;而实时检索只要你把页面收录、缓存、可读性做好,几周内就能见效。先用实时检索拿到可见度,再通过长期的第三方布局去影响下一轮训练语料,是更务实的节奏。
问:做了 GEO,多久能看到效果?
坦白说,这是目前整个行业都没有确切答案的问题,但有几个可参考的时间窗口:robots.txt 放行立即生效,但爬虫下次来访是数天到数周;JSON-LD 与内容改造需要搜索引擎重新抓取(1 到 4 周),再叠加 RAG 引用的延迟。实操建议:先跑一次基线检测记录各平台提及率,优化 4 周后再跑一次,有数据才能判断效果。